https://chocolemon.tistory.com/143
[텍스트 마이닝-분석] 단어동시출현행렬 및 CONCOR 분석
SNS 텍스트 분석을 하다 보면 텍스트 데이터에서 네트워크 분석이 필요할 때가 있습니다. 여러 개의 네트워크 분석 기법 중, 전체 데이터 내에서 유사한 맥락과 연결구조패턴을 갖고 있는 단어들
chocolemon.tistory.com
위 포스트에서 만든 파일을 가지고 CONCOR 분석과 시각화를 진행합니다.
Ucinet 프로그램을 다운받습니다. 최신 파일을 다운받으시면 됩니다.
https://sites.google.com/site/ucinetsoftware/download
Analytic Technologies - Download
TO DOWNLOAD, PRESS THE RED DOWNLOAD BUTTON BELOW. BUT YOU MIGHT WANT TO READ THE WHOLE PAGE FIRST
sites.google.com
UCINET 프로그램 활용에 대한 공식 문서는 다음을 참고하시면 됩니다.
How to use:
A tutorial by Bob Hanneman & Mark Riddle is available here: http://faculty.ucr.edu/~hanneman/nettext/.
Introduction to Social Network Methods: Table of Contents
faculty.ucr.edu
See also this great book:
Borgatti, S.P., Everett, M.G. and Johnson, J.C. 2018. Analyzing Social Networks. Sage Publications. 2nd Edition.
CONCOR 분석에 관한 설명은 안내 페이지 내
Contents of chapter 13: Measures of similarity and structural equivalence 에서 찾아보실 수 있습니다.
Ucinet을 실행하고 CONCOR 분석을 위한 네트워크 분석을 먼저 진행합니다.
네트워크 분석에 필요한 파일은 1) 단어동시출현행렬, 2) 전체 단어 빈도(단어동시출현행렬 단어 목록)
상단 메뉴에서 파란색 엑셀창처럼 보이는 Matrix Editor를 클릭합니다.
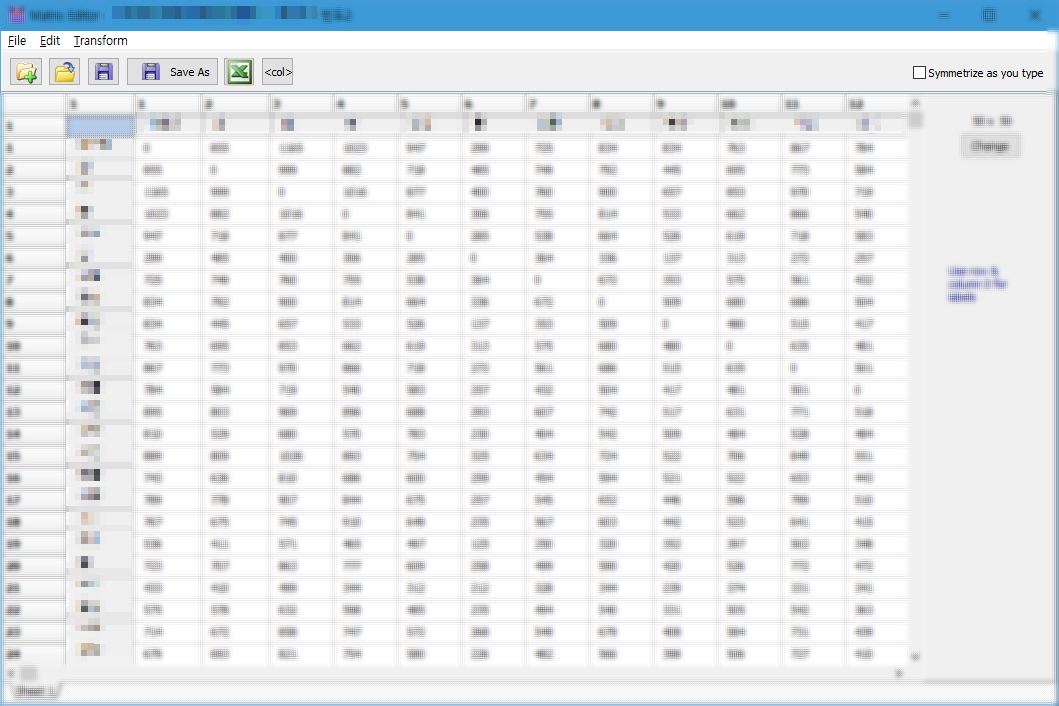
Matrix Editor 창에 단어동시출현행렬 엑셀 파일을 붙여넣기 합니다.
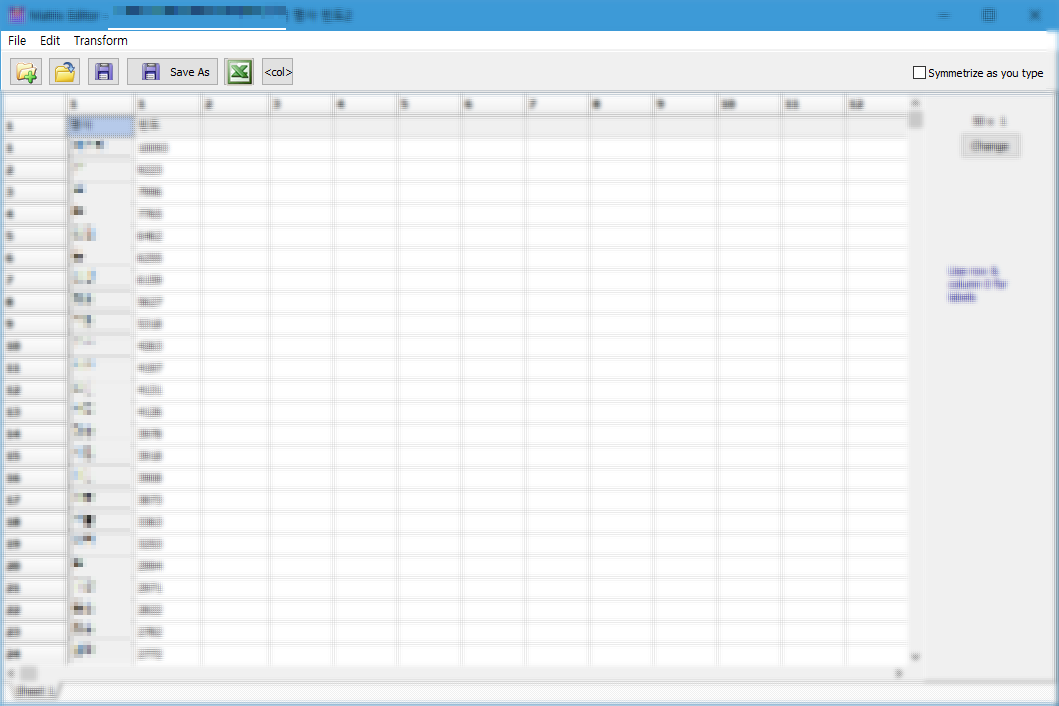
이 행렬 파일을 저장합니다.
이때 concor 분석용 저장 폴더를 하나 만들어 저장하는 것이 좋습니다. 추후에 만들 분석 파일들도 같이 저장하는 것이 분석 중이나 분석 후에 편하기 때문입니다.
( ※ 반드시 인덱스와 칼럼 모두 단어로 구성되어 있어야 합니다. 저장 전에 꼭 다시 한 번 확인해보세요! )
다음에는 단어동시출현행렬에 쓰인 단어들의 전체 단어 빈도를 maxtirx editor에 넣어서 저장합니다.
이름은 전체빈도인 것을 알아볼 수 있게 자유롭게 저장하시면 됩니다.
여기까지 잘 했으면 반은 끝났습니다.
이제 ucinet으로 저장한 파일을 가지고 네트워크를 그릴 차례입니다.
matrix editor 창은 끄고, 상단 메뉴에서 netdraw 메뉴를 클릭합니다.
NetDraw 창에서 Open UCINET Network Dataset 메뉴를 클릭합니다.
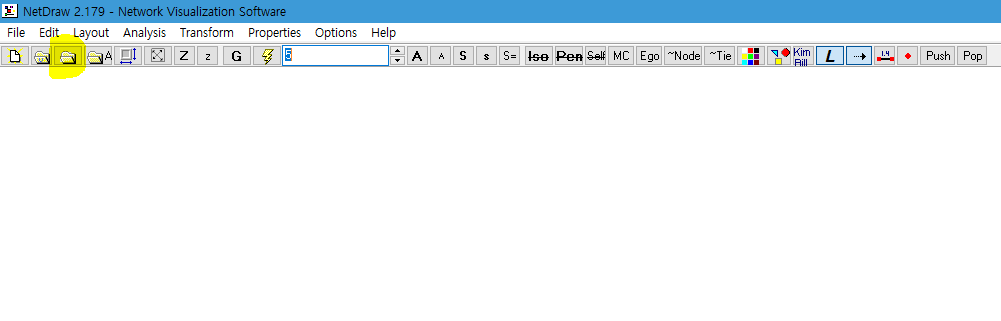
단어동시출현행렬을 저장한 파일을 열어줍니다.
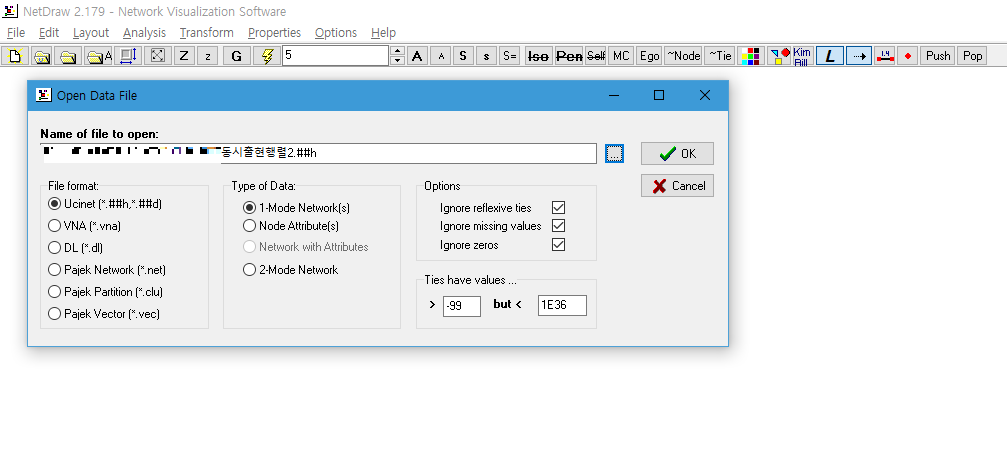
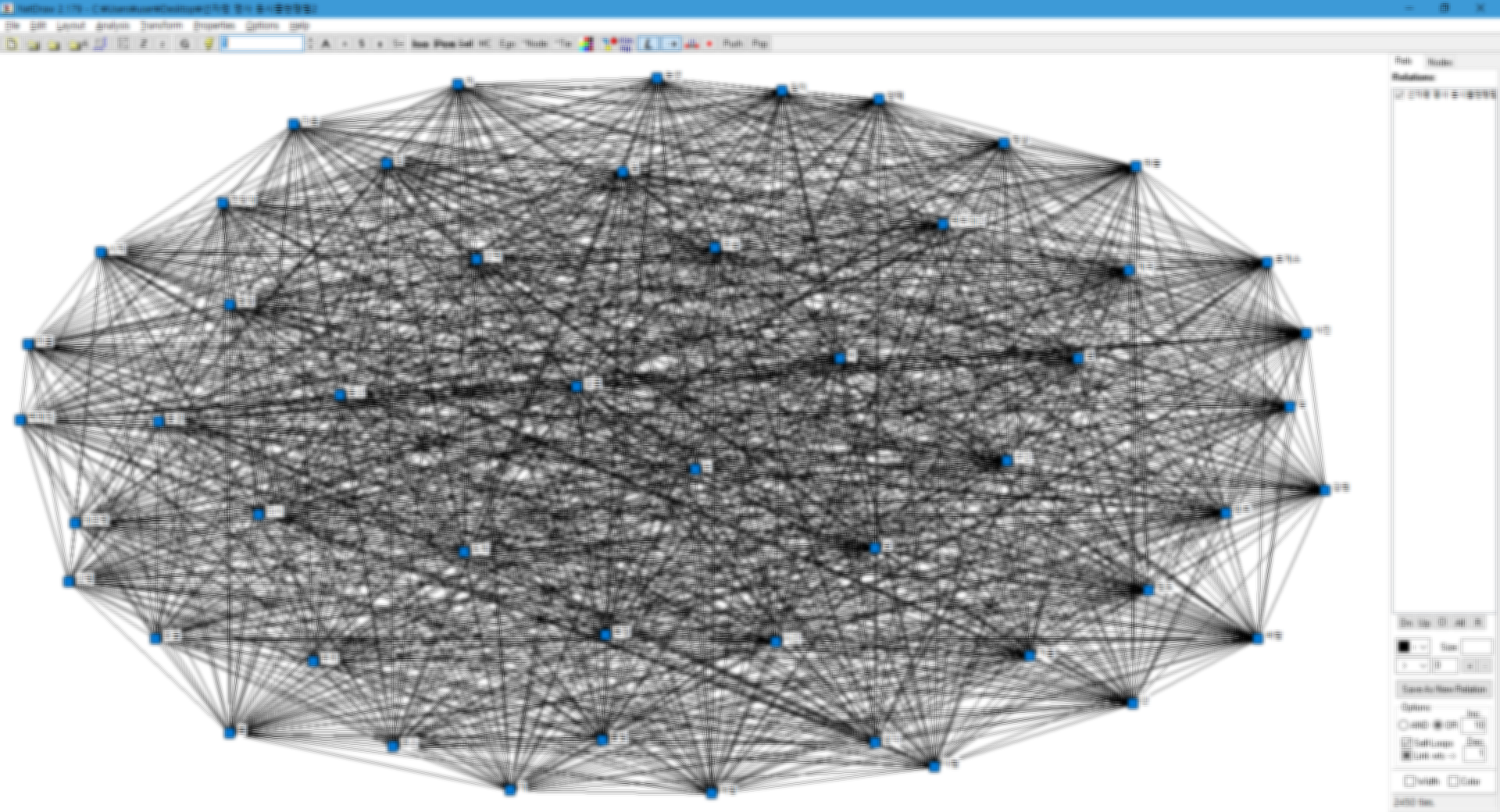
그럼 이렇게 노드(단어)가 선으로 이어진 네트워크 그래프가 생성됩니다.
이번에는 Open UCINET attirubte dataset 메뉴를 클릭하여 아까 전체 단어 빈도 파일을 만들 것을 열어줍니다.
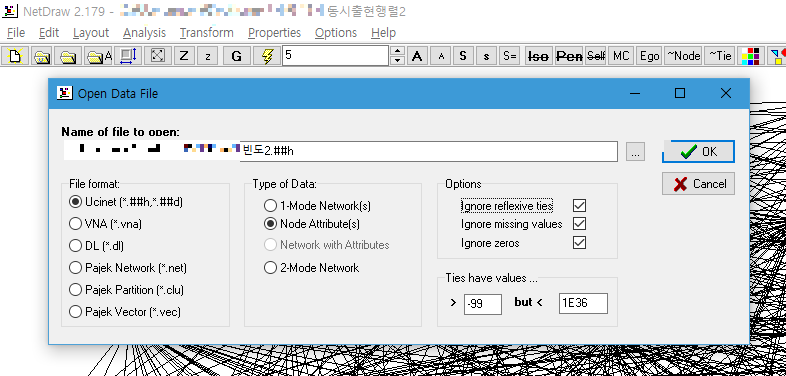
단어 빈도 파일을 추가하면 노드의 속성을 조절할 수 있습니다.
전체 단어 빈도의 크기가 클수록 노드의 크기도 커집니다.
노드의 최소 크기와 최대 크기는 연구자 임의로 조정할 수 있습니다.
저는 최소 5, 최대 25로 설정하였습니다.
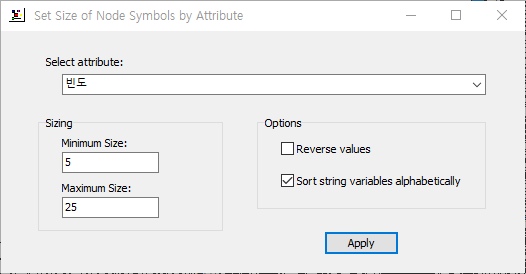
이제 네트워크 작성은 끝났으니 CONCOR 분석을 진행할 차례입니다.
NetDraw는 켜둔 상태로 UCINET 기본 화면으로 돌아와 상단 메뉴에서 Network 메뉴를 클릭합니다.
Roles & Positions 내 Structural 메뉴에 Concor 분석이 있습니다.
분석에 쓰이는 데이터가 서로 상호작용이 없는 텍스트 데이터이므로 Standard 를 선택해줍니다.
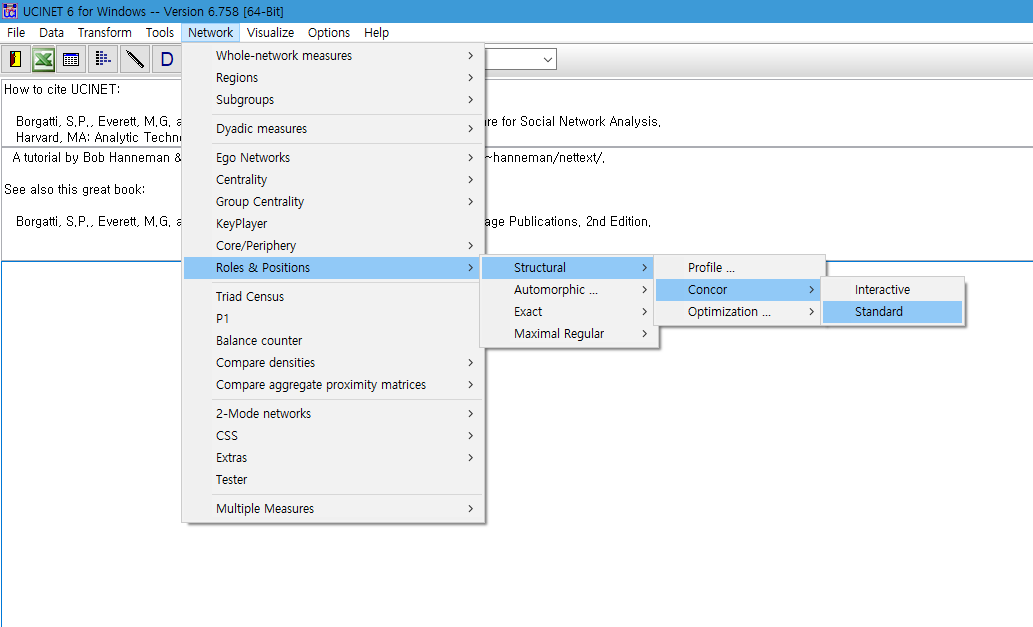
Input dataset에 단어동시출현행렬로 만든 network 파일을 넣어주고 아래 옵션들은 다음과 같이 설정해줍니다.
Max depth of splits는 추후 CONCOR 그래프를 그릴 때 만들어질 Cluster Diagram을 나누는 단계의 최대 횟수*입니다. 저는 기본 설정인 3으로 설정하였습니다.
(*3으로 설정하면 총 3번에 걸쳐 Cluster를 나누고, 5로 설정하면 5번에 걸쳐 Cluster를 나누게 됩니다. 자세한 설명은 공식 문서에서 찾아보실 수 있습니다.)
맨 밑 Output 3개의 저장경로는 앞서 만든 concor 저장 폴더로 지정해줍니다.
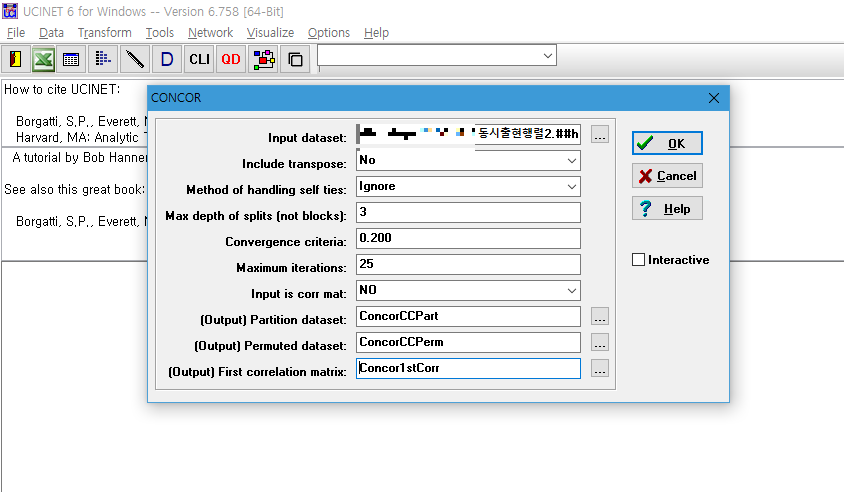
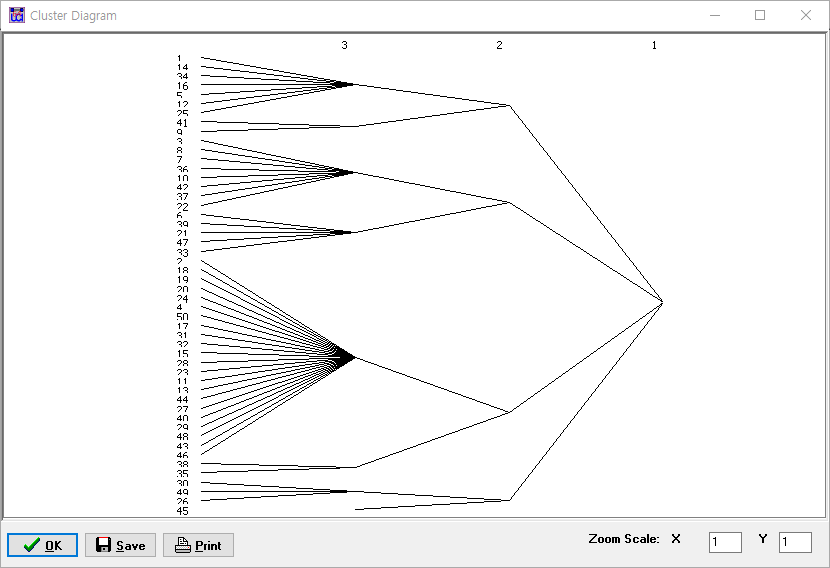
실행 결과 Clutser Diagram 과 ucinetlog.txt 파일이 생성됩니다.
Cluster Diagram에서 군집을 나누는 횟수에 따라 총 몇 개의 군집이 생성되는지 확인할 수 있습니다.
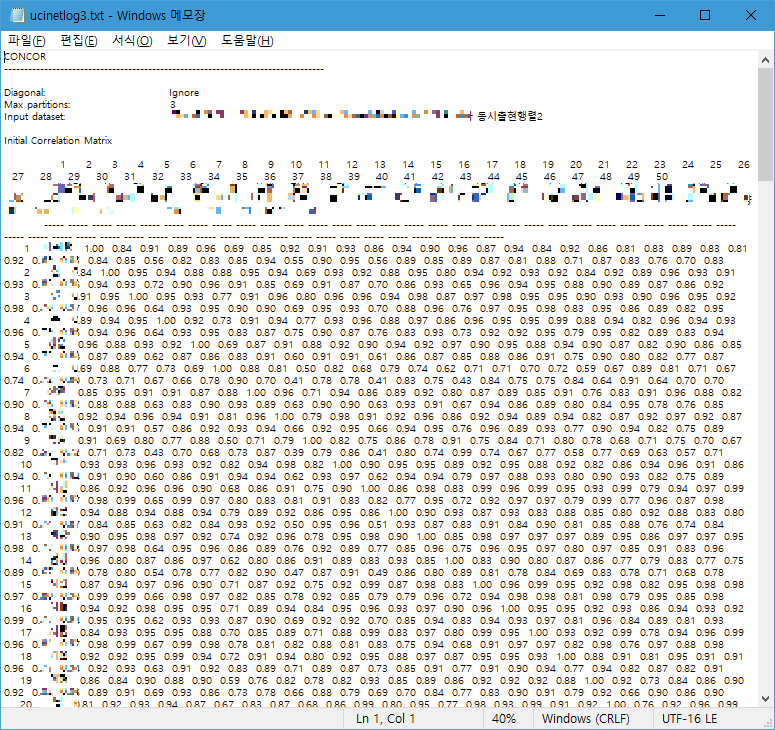
ucinetlog.txt 파일에서는 1)상관계수 값과 2)PARTITION DIAGRAM, 3)Blocked Matrix, 4)Density Matrix, 5)R-squared 값을 확인할 수 있습니다.
텍스트 파일 맨 밑에는 Output 파일 3개의 저장경로도 적혀있습니다.
이제 다시 NetDraw 창으로 돌아와 Open UCINET attribute dataset 을 클릭해서 방금 전에 만든 ConcorCCPart 파일을 추가해줍니다.
그다음 상단 Layout 메뉴에서 Group by Attribute를 클릭하고 Categorical Attribute를 선택합니다.
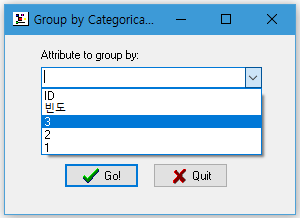
Attribute to group by에서 앞서 설정한 Max Depth of Splits의 숫자가 나타납니다.
저는 Cluster Diagram을 확인한 결과 3번 나눴을 때의 군집 수가 적절한 것 같아 3을 선택하였습니다.
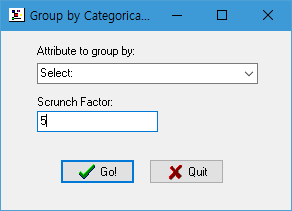
Scrunch Factor는 각 군집 내 요소들의 배치 정도를 지정합니다. 값이 작을수록 군집 내 요소간 거리가 멀어집니다. 값이 크면 노드들이 겹쳐져서 나중에 조정할 때 손이 많이 갑니다. 5로 설정했을 때 구성 요소가 많은 군집이 적절하게 배치된 것 같아서 5로 설정하였습니다.
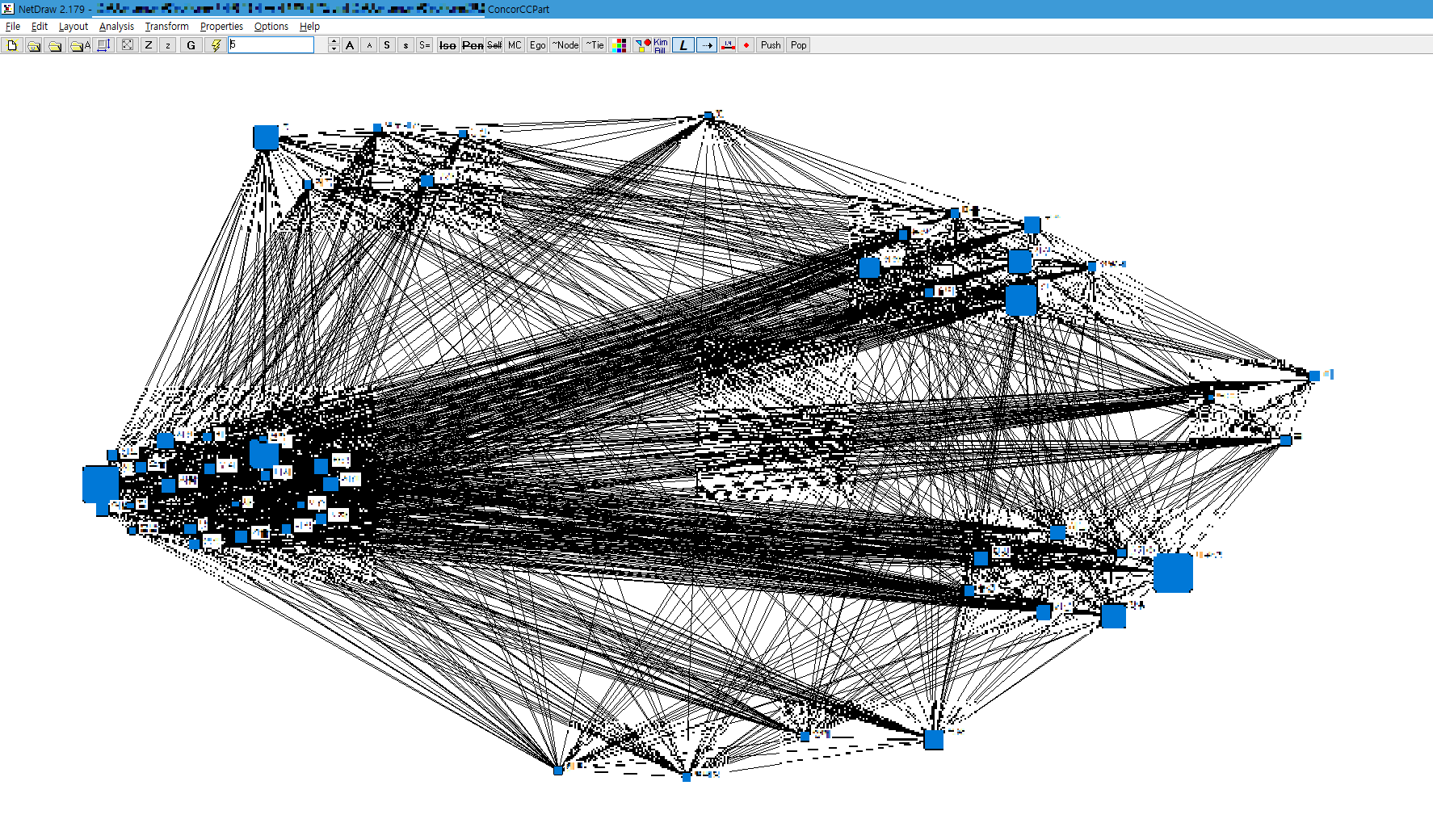
그럼 이렇게 군집별로 묶인 그래프가 생성됩니다.
각 군집별로 색상을 설정할 수도 있습니다.
상단 메뉴에서 다양한 색상의 정사각형이 있는 메뉴를 클릭하면 군집 단계별로 군집 색깔을 지정할 수 있습니다.
파스텔톤 팔레트로 예쁘게 구성할 수도 있겠으나, 무지개 색깔이 가장 설정하기 편하므로 빨주노초파남보.. 순으로 설정해보았습니다.
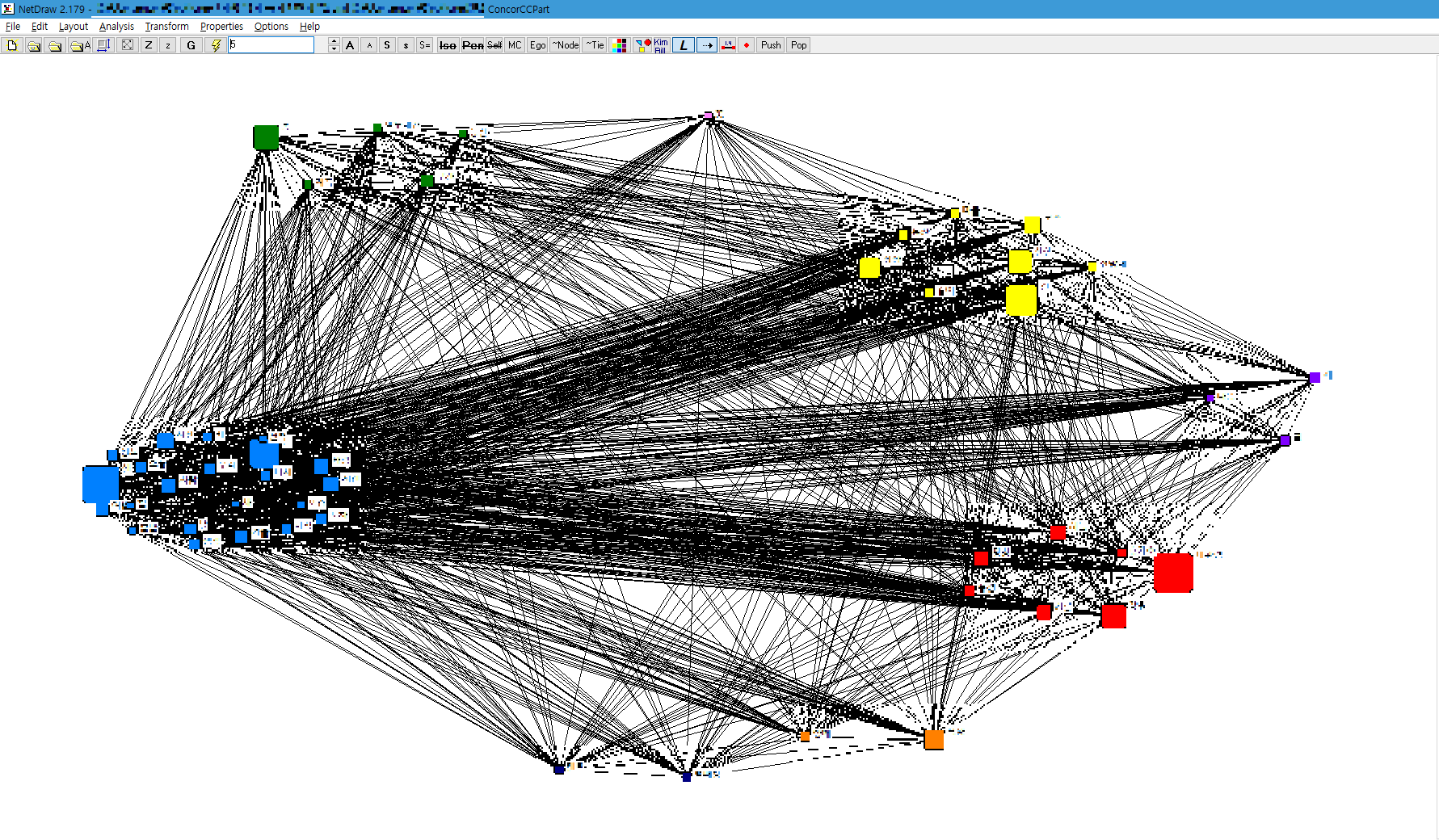
이후 군집 명명은 연구자의 몫입니다.
추가 문의는 댓글로 남겨주시면 답변해드리겠습니다.
'데이터 분석 > Python' 카테고리의 다른 글
| [텍스트 마이닝-정제] 주제와 관련 없는 문서 제거하기 (0) | 2023.12.27 |
|---|---|
| [텍스트 마이닝-지표 산출] TF-IDF 계산 및 문서 개수 합계 산출 (0) | 2023.11.17 |
| [텍스트 마이닝-분석] 한글 N-gram 분석 (0) | 2023.09.18 |
| [텍스트 마이닝-분석] 단어동시출현행렬 및 CONCOR 분석 (0) | 2023.09.18 |
| [텍스트 마이닝-분석] TF-IDF: sklearn Tfidfvectorizer 사용 (0) | 2023.09.17 |




댓글